Résumé du cours Cyber de l'IA
Comportement du modèle sur les données d'entrainement
Le sur-apprentissage - de l'importance d'un ensemble de validationLors de l'apprentissage le modèle apprend à bien classifier les données qu'on lui présente, les données dites d'apprentissage. Plus celles-ci sont de bonnes qualités, c'est à dire diverses et représentatives des données qu'on souhaite ensuite labelliser, plus le modèle sera performant sur ces données cibles. Savoir quand arrêter un entrainement reste un véritable enjeu:
Pour éviter le sur-apprentissage, il est primordial d'utiliser des données de validation, elles ne sont pas utilisées pour apprendre le modèle, mais pour arrêter l'apprentissage. L'autre problème du sur-apprentissage, c'est que le modèle se comporte alors différemment sur les données d'apprentissage pour lesquelles il est très performant que sur les données qu'il n'a jamais vu. Il devient alors facile de réaliser une attaque d'inférence d'appartenance sur un modèle sur-appris. |
Les attaques d'inférence d'appartenanceL'objectif de ces attaques est de déterminer si une donnée a été utilisée à l'entrainement d'un modèle. Si elles sont souvent difficiles à réaliser par un attaquant (il faut avoir accès à la donnée), ces attaques permettent néanmoins d'évaluer une différence de comportement, une forme de mémorisation des données d'apprentissage. Prédictions d'un modèleSur les données d'apprentissage un modèle va non seulement avoir de meilleurs performances (accuracy etc.). Mais il va aussi faire des prédictions avec plus de 'confiance' (façon de parler). Cela se voit avec ce que l'on appelle les 'logits'. Les logits sont le vecteur de sortie du modèle, sa taille correspond au nombre de classes analysées. En effet à chaque image un classifieur n'associe pas directement une prédiction mais un vecteur de prédictions avec un score de 'ressemblance' par classe. Ce sont ces scores que l'on appelle les 'logits', la classe qui obtient le score le plus élevé est la classe prédite. Fonctionnement des attaques d'inférence d'appartenanceSur les données d'entrainement un modèle va avoir de plus grand logits, cela est particulièrement vrai pour
les modèle sur-appris.
De nombreuses attaques d'inférence d'appartenance analysent les valeurs des logits (en particulier les valeurs
maximales) pour déduire si la données a été utilisée à l'apprentissage.
L'une des plus célèbres de ces attaques est LIRA |
Comment mettre au point une attaque d'inférence d'appartenanceDans un premier temps les valeurs les plus élevées des logits nous donnent beaucoup d'informations. Mais une combinaison de ces valeurs peut nous donner bien plus d'informations, c'est ce que nous appelons la hingeloss. Elle est égale à:
RemarqueIl est néanmoins difficle de comparer les hingeloss entre des instances de classes différentes. Certaines classes sont en effet plus facile à classifier que d'autres. Il faudra donc mener l'analyse classe par classe. Les classes difficiles à classifier présentent des hingeloss très dispersées, il sera alors plus facile de distinguer les instances pour lesquelles le modèle se comporte particulièrement bien. |
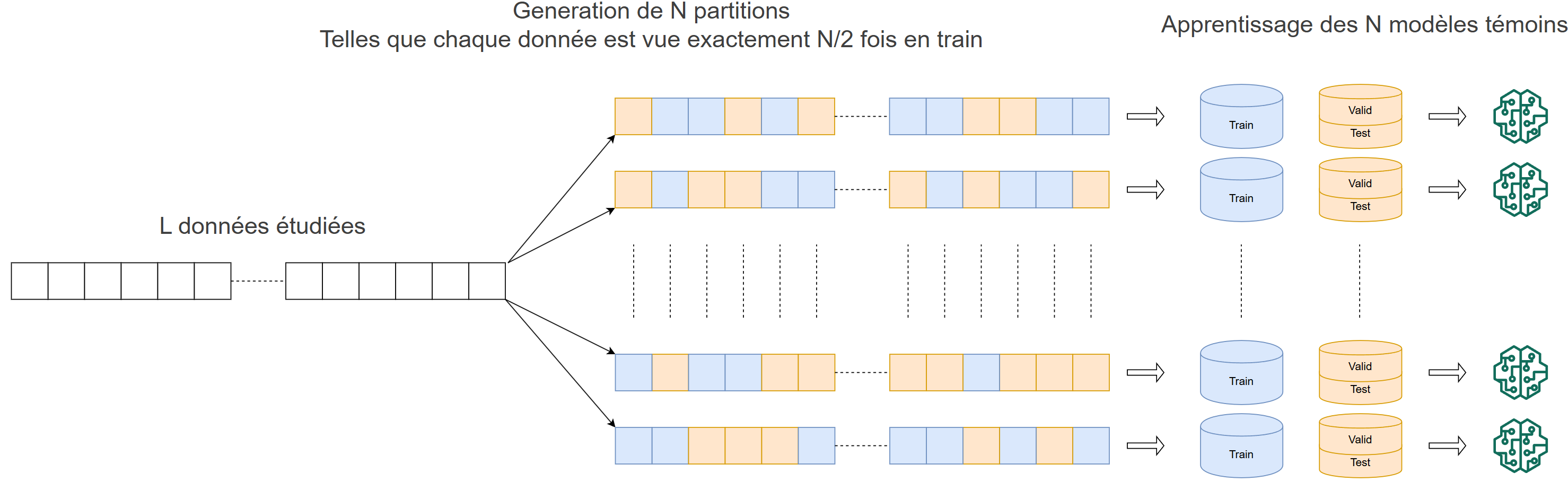
L'attaque LIRA de Carlini et al.: utilisation des modèles "shadow"Pour avoir une idée de la signification de la hingeloss par instance, l'idée est d'apprendre de nombreux modèles que l'on maitrise, appelés "modèles shadow".
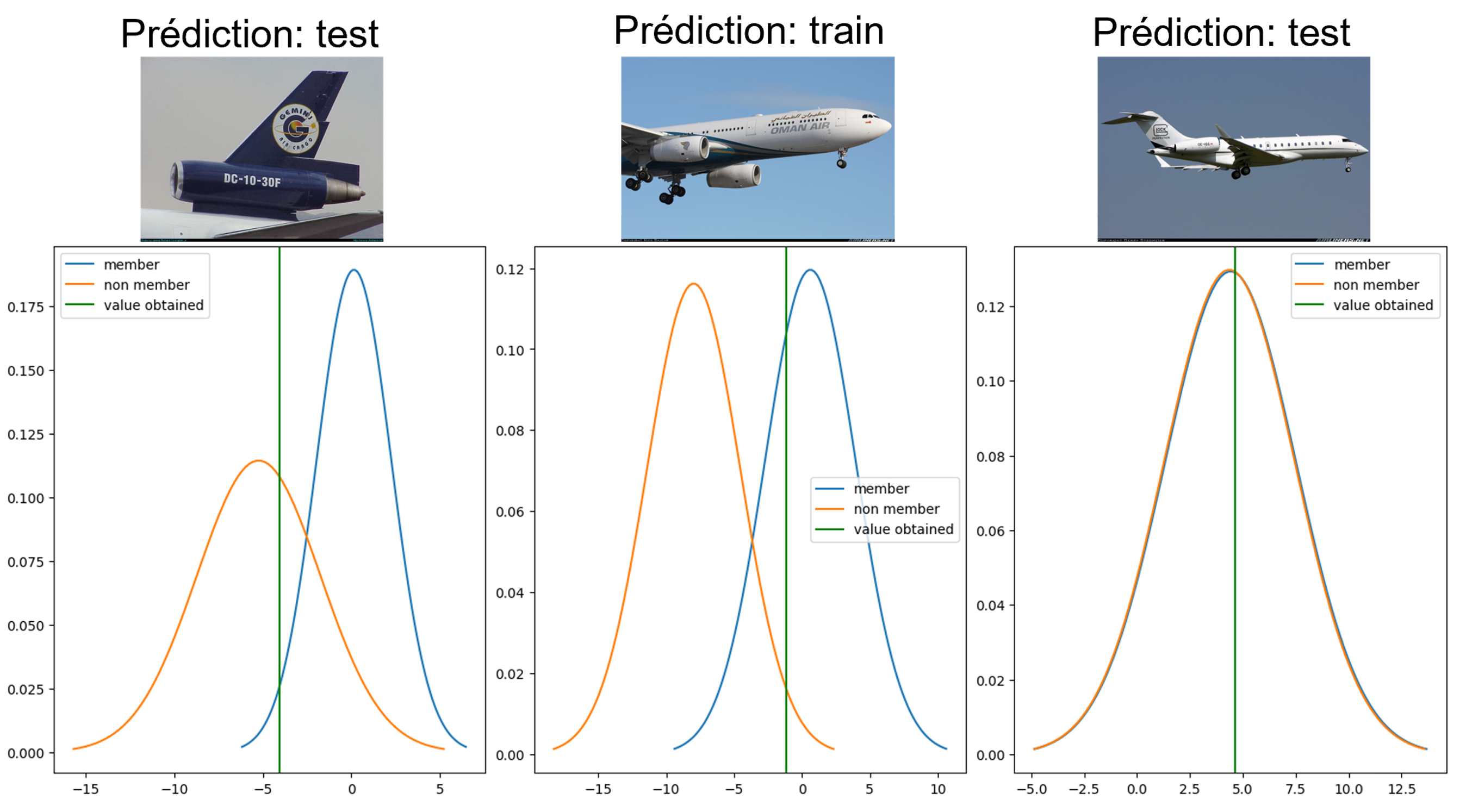
Ainsi pour chaque données d'intéret on obtient deux distributions de hingeloss, une pour les modèles shadow qui l'ont vu à l'apprentissage et l'autre pour ceux qui ne l'ont pas vu.
Pour faire ce calcul on estime les distrubtions à des gaussiennes, pour chaque donnée on a ainsi la moyenne et l'écart type de la gaussienne 'in' correspondant aux modèles l'ayant vu à l'apprentissage, et la moyenne et l'écart type de la gaussienne "out" correpsondant aux modèles shadow ne l'ayant pas vu à l'apprentissage. La figure 3 fournit un exemple d'utilisation de l'attaque |